字串相當於將許多字元集合在一起,例如”hello world”就是由11個字元組合起來的,在C或是Objective-C中,字元與字串用的符號是不一樣的,C或是Objective-C字元用單引號「’」表示而字串用雙引號「”」表示,但Swift不論是字元或是字串都是用雙引號來表示。
資料型態String為字串,Character為字元,兩者都是結構,屬於value type。因此,當把一個字串型態的變數指定給另一個變數時,兩變數內容雖然一樣,但彼此之間已經擁有獨自的記憶體區段,之後改變任何一個變數內容時都不會對另外一個變數內容造成影響。
5.1 格式
使用兩個雙引號包圍住的文字預設型態為String稱為字串,例如:
let str = "hello, world"
除了兩個雙引號外,多行文字字串可以使用連續三個雙引號包圍住文字,例如:
let str = """
第一行文字
第二行文字
第三行文字
"""
print(str)
/* Prints
第一行文字
第二行文字
第三行文字
*/
若使用三個雙引號的多行文字字串在行尾的地方出現反斜線「\」,代表兩行合併成一行,如下:
let str = """
第一行文字 \
這也是第一行文字
這是第二行
"""
print(str)
/* Prints
第一行文字 這也是第一行文字
這是第二行
*/
在多行文字中行尾出現「\」符號代表合併兩行,若在字串中間出現此符號代表與後面的字元合在一起是一個跳脫字元(escaped character),具有特殊的意義。例如\0代表ASCII碼為0的字元,\n代表換行,\r代表將游標移到行首,\\代表一個反斜線,\t代表tab,\”代表雙引號,\’代表單引號。例如要在字串中出現雙引號,就必須使用「\”」,如下:
let str = "What is difference between \' and \"?"
// str == What is difference between ' and "?
如果字串本來就要輸出的「\」符號,例如「c:\name」,這時就必須將字串改為「c:\\name」,否則字串輸出時「\n」會變成換行。如果不想要使用「\\」符號的話,可以使用「#”」來包圍字串,這樣字串中的「\」符號就真的是字串中的一部分了。例如:
let str = #"c:\name"#
print(str)
// Prints "c:\name"
字串可看做是一個字元陣列。因此,使用For-In迴圈可以依序取出字串中的每一個字元,例如:
let str = "Swift"
for ch in str {
print(ch)
}
// S
// w
// i
// f
// t
也可以將一個字元陣列合併成一個字串,例如:
let chars: [Character] = ["S", "w", "i", "f", "t"]
let str = String(chars)
// str == "Swift"
由於字串或字元都是使用雙引號,因此當沒有明確指定資料型態的情況下,預設型態為String,例如下面程式碼中常數s的型態為字串,如果要為字元必須明確指定型態。
let s = "a"
let c: Character = "a"
print(type(of: s))
// Prints "String"
print(type(of: c))
// Prints "Character"
兩個字串相加,使用符號「+」或是「+=」即可,例如:
var str = "hello"
str += " world"
print(str)
// Prints "hello world"
但字串的「+」或是「+=」只能用在整個運算式都是字串,如果運算式中有其他的型態,就會出現錯誤訊息了,例如:
let temp = 25
var str = "現在氣溫為"
str += temp
// Cannot convert value of type 'Int' to expected argument type 'String'
這時就需要將數字25轉成字串的25才能與str合併,例如:
let temp = 25
var str = "現在氣溫為"
str += String(25)
// str == "現在氣溫為25"
或是使用「\()」在字串中嵌入其他變數或常數,型別不一致的問題編譯器自動就幫我們處理掉了,例如:
let temp = 25
var str = "現在氣溫為\(temp)"
print(str)
// Prints "現在氣溫為25"
5.2 字串索引值
既然在概念上字串是字元陣列,以其他語言而言,使用陣列索引值就可以取得字串中的第幾個字元,例如[3]代表要取字串的第4個字元,或者透過索引值取得子字串。但我們發現Swift的字串索引值型態不是數字,而是String.Index結構,這個結構用來儲存字串中每個字元的位置。由於String用了很彈性的文字編碼,因此字串索引值無法使用整數型態。
舉個例子,在歐洲文字中常見的「é」這個字需要使用Unicode方式產生,但有幾種方式。下面第一種方式\u{e9} (代表Unicode碼U+00E9)即是「é」的Unicode;第二種方式使用了兩個Unicode,一個是U+0065,然後接一個U+0301,第一個Unicode其實是小寫英文字母e,第二個Unicode為é上面的那一撇,顯示時會自動將這兩個Unicode合併起來,所以會顯示é。第三種方式,既然我們已經知道U+0301可跟前面的英文字母合併,形成英文字母上方有一撇的字母,所以就先輸入一個英文字母e再加上\u{301},因此顯示時會跟第二種方式一樣合併成é。而這三種方式的資料型態都是Character。
let e1: Character = "\u{e9}"
let e2: Character = "\u{65}\u{301}"
let e3: Character = "e\u{301}"
// e1 == é
// e2 == é
// e3 == é
從這個例子可以知道,雖然輸出時看起來是一個字元,資料型態也是Character,但是內部儲存這個字元所需要的記憶體大小是不一樣的。為了解決每個字元實際大小可能都不同的問題,String內部使用了Unicode Scalars編碼法。這個編碼法可以將實際顯示時的第一個字、第二個字…第n個字對映到記憶體中實際的字元位置。我們再看下面這個例子,Hi後面接了一個表情符號,如果使用utf8編碼,這個字串長度為6,因為表情符號用了4個utf8編碼;如果換成utf16,字串長度變成4,表情符號用了2個utf16編碼;最後的unicodeScalars編碼出來的字串長度就是看到的字元數3了,這時表情符號使用了utf32編碼。
let s = "Hi?"
print(s.utf8.count)
// Prints "6"
print(s.utf16.count)
// Prints "4"
print(s.unicodeScalars.count)
// Prints "3"
既然字串相當於字元陣列,但每一個字元所需要的儲存空間卻不是固定的,於是用字元組合出來的字串中的每一個字元實際大小也就都不一定,這時自然就無法使用整數型態的索引值去疊加出指定位置的字元,因此String中每個字元的索引值必須以結構來儲存。
String中有一個名稱為indices的屬性,其型態DefaultIndices,這是一個符合Collection協定的型態。這個型態儲存了字串中所有的String.Index結構。下面這個例子說明如何透過For-In迴圈將屬性indices中每一個元素經歷一遍,並且根據每一個元素內容取得字串中的每一個字元。
let str = "Swift"
for i in str.indices {
print("\(str[i]) => \(i)")
}
// S => Index(_rawBits: 1)
// w => Index(_rawBits: 65793)
// i => Index(_rawBits: 131329)
// f => Index(_rawBits: 196865)
// t => Index(_rawBits: 262401)
String型態中的下標語法,即[n],被設計為接受String.Index型態的參數,因此會從String.Index結構中取得每個字元所在位置的資訊,這時如果直接填入整數,例如str[2] 必定得到錯誤訊息。所以,如果我們要取得字串中的第二個字元,只要先得到indices中的第二個元素就可以了。
雖然屬性indices的資料型態DefaultIndices符合Collection協定,但DefaultIndices型態並沒有提供下標語法讓我們可以很容易的取得任一元素,因此需要透過String型態中的各種索引值操作方法與屬性來取得我們想要的索引值。例如:
let str = "Swift"
let first = str[str.startIndex]
// first == "S"
let begin = str.index(str.startIndex, offsetBy: 1)
let end = str.index(str.startIndex, offsetBy: 3)
let wif = str[begin...end]
// wif == "wif"
上面這段程式碼中,屬性startIndex會取得字串第一個字元的索引值,然後再透過字串的下標語法就可以取得字元”S”。若要取得原字串中間的字,需要根據startIndex屬性再往後加幾個字,這要透過index(_:offsetBy:)方法來計算。第一個參數為起始索引值,offsetBy參數則是從第一個參數的位置加多少個字,所以上面程式中的常數begin為第二個字”w”所在的位置,常數end為第四個字”f”所在的位置,接下來使用範圍運算子「…」或「..<」配合字串下標就可以取出原字串中第二個字到第四個字的子字串了。
標準函數庫中提供的子字串處理,都是透過String.Index來操作,使用上並不是很習慣。我們用extension擴充一下String功能,透過我們習慣的整數索引值來操作字串。擴充語法請參考第8章結構與類別,下標語法請參考第11章下標。
extension String {
subscript(n: Int) -> Character {
let index = self.index(self.startIndex, offsetBy: n)
return self[index]
}
subscript(lower: Int, upper: Int) -> Substring {
var _upper = upper
if _upper >= self.count {
_upper = self.count - 1
}
let begin = self.index(self.startIndex, offsetBy: lower)
let end = self.index(self.startIndex, offsetBy: _upper)
return self[begin...end]
}
}
let str = "Hi,?. Today is a good day."
print(str[3])
// Prints "?"
print(str[6, 10])
// Prints "Today"
透過這個extension,使用str[3]就代表字串中的第4個字,str[6, 10]就代表要取出字串中的第7個字到第11個字。其他常用的屬性與方法,稍後詳加說明。
5.3 子字串
字串型態除了String外,還有Substring型態,由名稱可以知道,Substring專門用在子字串。由於String與Substring都符合StringProtocol協定的規範,因此Substring能做的事情幾乎跟String一樣。String的許多操作方法會傳回Substring型態的字串,例如prefix(_:)。下面的程式碼中,原本字串str比較長,而我們只需要前5個字就好,因此透過prefix(_:)函數取得字串的前5個字並放入變數substr中。
var str = "hello, world"
var substr = str.prefix(5)
print(substr)
// Prints "hello"
print(type(of: substr))
// Prints "Substring"
從執行結果可以發現,變數substr的資料型態為Substring,這個型態所擁有的方法與String型態幾乎一模一樣,但特性是儲存的資料幾乎不佔記憶體。從程式碼來說明,變數substr會參考str的記憶體區段,然後只是透過索引值來顯示str的部分內容而已,因此substr幾乎不佔記憶體空間。從圖上來看,下圖中str的內容hello與subtring的內容hello其實是同一個。
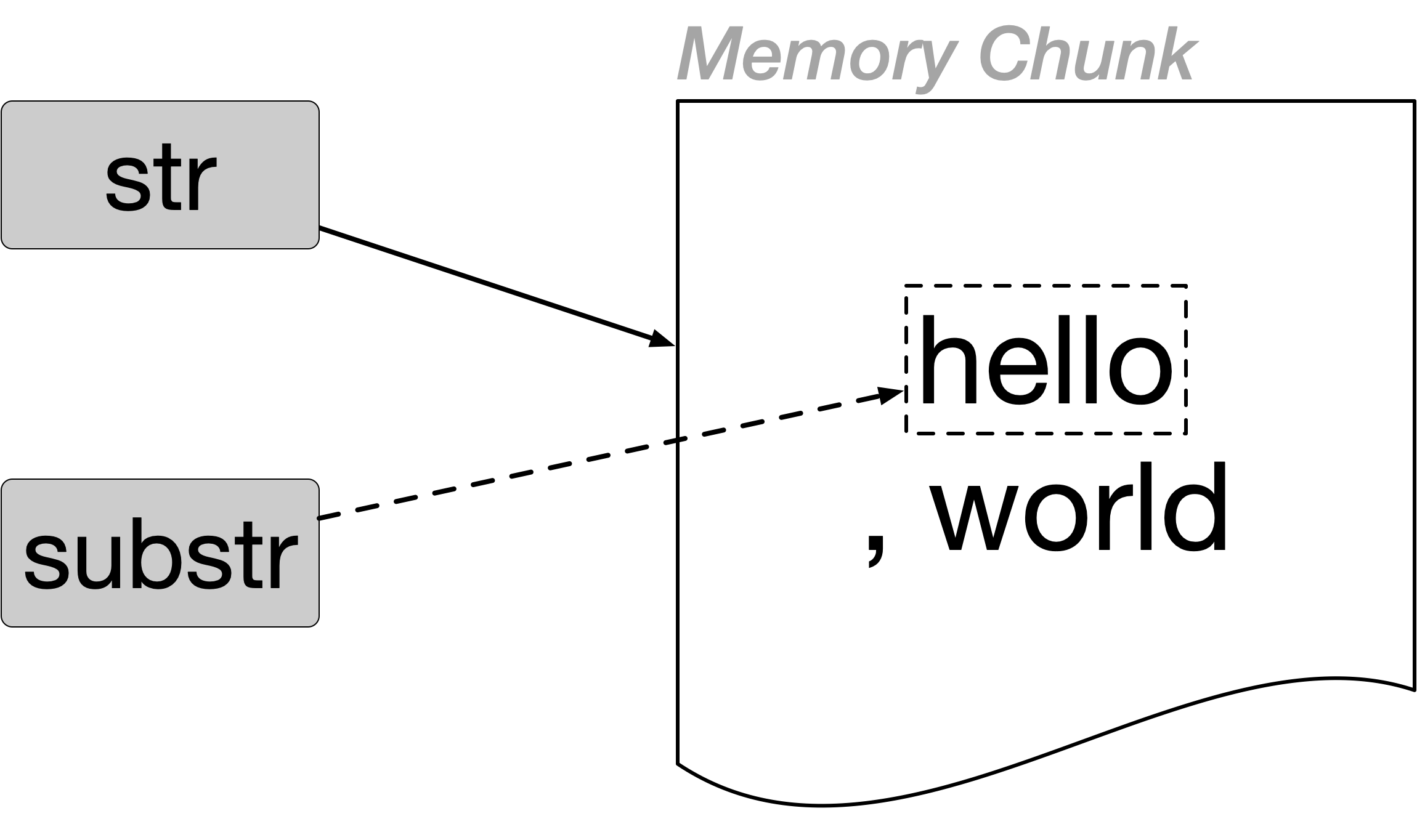
但是當str或substr內容改變時,記憶體就不再共享,如下圖是修改了str的內容後的記憶體示意圖。str的記憶體空間為新配置的,放的是修改後的內容Hi,而原本substr所使用的記憶體內容並沒有改變,這代表了substr所佔有的記憶體空間有很大一部份浪費了,因為substr只需要”hello”那一塊記憶體就足夠。

因此,如果取出的子字串需要長時間使用且原本的字串內容不再需要,或者原本的字串內容做了修改,此時應該將子字串轉成一般字串,這樣原本比較長的字串所佔用的記憶體資源就可以釋放。將Substring型態的子字串轉成String型態,程式碼如下:
let newStr = String(substr)
這個例子的字串長度其實不長,佔用的記憶體空間有限,所以要不要轉成String型態其實影響不大,但如果原本的字串長度很長,並且也原字串事後也修改了內容,這時就建議將Substring轉成String以節省寶貴的記憶體空間。
5.4 Character常用屬性與函數
判斷是否為ASCII碼
名稱: isASCII
說明: ASCII碼為美國資訊交換標準碼,原本定義了128個,後來擴充到256個,我們在鍵盤上打的任何一個英文字母與符號都經過了ASCII編碼。但現在電腦上能夠顯示的文字已經遠超過256個,因此,這個屬性是用來判斷儲存的文字編碼是不是在ASCII編碼範圍內。如果字元是中文字或表情符號,編碼就不在ASCII碼範圍內。
範例:
let ch1: Character = "台"
print(ch1.isASCII)
// Prints "false"
let ch2: Character = "W"
print(ch2.isASCII)
// Prints "true"
取得ASCII碼
名稱: asciiValue
說明: 如果字元編碼是在ASCII碼範圍內,可以透過asciiValue屬性取得編碼。如果字元不屬於ASCII編碼,此屬性內容為nil。
範例:
let arr: [Character] = ["a", "b", "c", "*", "/"]
for ch in arr {
if ch.isASCII {
print("\(ch): \(ch.asciiValue!)")
}
}
// a: 97
// b: 98
// c: 99
// *: 42
// /: 47
判斷是否有大寫與小寫之分
名稱: isCased
說明: 判斷字元是否具有大寫與小寫的差異,例如英文的26個字母有大小寫的不同。
範例:
print(("a" as Character).isCased)
// Prints "true"
print(("," as Character).isCased)
// Prints "false"
判斷是否為貨幣符號
名稱: isCurrencySymbol
說明: 例如符號「$」或是歐元符號「€」都屬於貨幣符號。
範例:
print(("$" as Character).isCurrencySymbol)
// Prints "true"
print(("€" as Character).isCurrencySymbol)
// Prints "true"
判斷是否為16進位符號
名稱: isHexDigit
說明: 16進位符號包含了數字0-9以及英文A-F或a-f。
範例:
print(("f" as Character).isHexDigit)
// Prints "true"
print(("5" as Character).isHexDigit)
// Prints "true"
判斷是否為文字
名稱: isLetter
說明: 例如英文26字母或中文字這些既非數字也非符號的字屬於文字。
範例:
print(("台" as Character).isLetter)
// Prints "true"
print(("h" as Character).isLetter)
// Prints "true"
print(("-" as Character).isLetter)
// Prints "false"
判斷是否為小寫或是大寫
名稱: isLowercase、isUppercase
說明: 判斷是否為小寫或是大寫。
範例:
print(("A" as Character).isUppercase)
// Prints "true"
print(("a" as Character).isLowercase)
// Prints "true"
判斷是否為數學符號
名稱: isMathSymbol
說明: 例如「+」、「(」、「>」
範例:
print(("+" as Character).isMathSymbol)
// Prints "true"
print(("∫" as Character).isMathSymbol)
// Prints "true"
print(("∞" as Character).isMathSymbol)
// Prints "true"
判斷是否為空白或是換行
名稱: isWhitesapce、isNewline
說明: 空白除了SPACE之外,換行、TAB也都算是空白
範例:
print(("\n" as Character).isNewline)
// Prints "true"
print(("\n" as Character).isWhitespace)
// Prints "true"
判斷是否為標點符號
名稱: isPunctuation
說明: 例如「,」、「.」或「;」這些符號。
範例:
print(("," as Character).isPunctuation)
// Prints "true"
print(("." as Character).isPunctuation)
// Prints "true"
判斷是否為數字或全數字。
名稱: isNumber、isWholeNumber
說明: 阿拉伯數字在這兩個屬性上必定都為true,但非阿拉伯數字有些也算數字,例如中文的「貳」或「千」。isWholeNumber用來判斷字元是否全部都為數字,例如「½」雖然是數字,但本身由三部分組成,並非全部都是數字。
範例:
print(("貳" as Character).isNumber)
// Prints "true"
print(("貳" as Character).isWholeNumber)
// Prints "true"
print(("½" as Character).isNumber)
// Prints "true"
print(("½" as Character).isWholeNumber)
// Prints "false"
判斷是否為符號
名稱: isSymbol
說明: 符號是有定義的,某些特定的編碼屬於符號,例如表情符號中的符號類。
範例:
print(("©" as Character).isSymbol)
// Prints "true"
print(("?" as Character).isSymbol)
// Prints "true"
5.5 String常用屬性與函數
這邊列出的屬性與函數大部分是String型態專屬與常用的,另外還有許多函數是與陣列通用,例如隨機取出字元randomElement()、將字串內容反轉reversed()、自帶迴圈forEach(_:)…等,這些函數請參考第4章聚集型態。
判斷是否為空字串
名稱: isEmpty
說明: 若字串內沒有任何字元,此屬性傳回true,否則傳回false。
範例:
let str = ""
print(str.isEmpty)
// Prints "true"
傳回字串長度
名稱: count
說明: 此屬性傳回在指定編碼法下的字串長度,預設編碼法為Unicode Scalars,因此count傳回實際看到的字元數。
範例:
let str = "Hi,?"
print(str.count)
// Prints "4"
傳回字串第一個字與最後一個字
名稱: first、last
說明: 此屬性傳回字傳的第一個字元與最後一個字元,若字串為nil,傳回nil。
範例:
var str = "Hello, playground"
print(str.first!)
// Prints "H"
print(str.last!)
// Prints "d"
取得字串開始與結束索引值
名稱: startIndex、endIndex
說明: 屬性startIndex傳回字串第一個字元的索引值,而要注意的是屬性endIndex並非最後一個字元的索引值, endIndex會比最後一個字元的索引值再大一點,所以要得到最後一個字元的索引值必須是結束索引值的前一個索引值。若startIndex與endIndex相等表示該字串為空字串。
範例:
var str = "Hello, playground"
print(str[str.startIndex])
// Prints "H"
let before = str.index(before: str.endIndex)
print(str[before])
// Prints "d"
索引值加減
名稱: index(_:offsetBy:)
說明: 字串的索引值為String.Index結構,因此無法直接加減Int型態的數字,必須使用index(_:offsetBy:)來加減。運算完的索引值不可超過原字串索引值範圍,否則程式會當掉。
範例: 印出字串索引值從開頭位置再加4個字元的內容,也就是第5個字元。
var str = "Hello, playground"
let index = str.index(str.startIndex, offsetBy: 4)
print(str[index])
// Prints "o"
索引值加1與減1
名稱: index(after:)、index(before:)
說明: index(after:)傳回輸入索引值的下一個字元的索引值;index(before:) 傳回輸入索引值的上一個字元的索引值。
範例: 印出第2個字元與最後一個字元。
var str = "Hello, playground"
let after = str.index(after: str.startIndex)
let before = str.index(before: str.endIndex)
print(str[after])
// Prints "e"
print(str[before])
// Prints "d"
計算兩個索引值差距幾個字元
名稱: distance(from:to:)
說明: 輸入兩個索引值後計算這兩個索引值差距多少個字元。
範例: firstIndex與lastIndex的差距等於字串長度。
var str = "Hello, playground"
let n = str.distance(from: str.startIndex, to: str.endIndex)
// n == 17
// n == str.count
尋找字串
名稱: range(of:)、range(of:range:)
說明: 在字串中尋找特定字串,如果找到,傳回特定字串所在位置的索引值範圍,若找不到傳回nil。參數range可以設定搜尋範圍,預設值為全部字串。
範例:
let str = "ABCDEFG"
if let range = str.range(of: "CDE") {
print(str[range.lowerBound])
// Prints "C"
print(str[range.upperBound])
// Prints "F"
}
範例: 藉由改變搜尋範圍找出字串中所有關鍵字位置,例如列出A所在的位置。
let str = "XABCDEABAHGA"
var range = str.startIndex..<str.endIndex
while let r = str.range(of: "A", range: range) {
let distance = str.distance(
from: str.startIndex,
to: r.lowerBound
)
print(distance, terminator: " ")
range = r.upperBound..<str.endIndex
}
// Prints "1 6 8 11"
取得指定網址內容
名稱: init(contentsOf:)
說明: 經由網址取得該網址內容。String類別只能取得文字內容,若網址內容為二位元格式(例如jpeg、mp3…等),應使用Data類別。
範例:
do {
let url = URL(string: "https://www.apple.com")
let html = try String(contentsOf: url!)
print(html)
// Prints "<!DOCTYPE html>..."
} catch {
print(error)
}
讀取檔案內容
名稱: init(contentsOfFile:)
說明: 經由檔名取得該檔案內容。String類別僅能讀取文字類型檔案,如檔案內容為二位元格式,應使用Data類別。
範例: 請將要讀取的文字檔拖放到Playground專案左側的Resources資料夾內,或者建立macOS的Command Line Tool專案。下面程式碼是Playground專案。
do {
let filename = Bundle.main.path(forResource: "readme", ofType: ".txt")
let text = try String(contentsOfFile: filename!)
print(text)
} catch {
print(error)
}
將資料寫入檔案
名稱: write(_:)
說明: 將字串寫入檔案中,檔案原有內容會被覆蓋。
範例: 此範例需建立macOS的Command Line Tool專案,Playground專案無法將資料寫入檔案。
do {
let url = URL(fileURLWithPath: "/tmp/readme.txt")
try "hi,?".write(to: url, atomically: true, encoding: .utf8)
} catch {
print(error)
}
附加
名稱: append()
說明: 在字串尾端附加一個字元或另一字串。
範例:
var str = "hello"
str.append(", world")
// str == "hello, world"
插入
名稱: insert(_:at:)、insert(contentOf:at:)
說明: 將字元或字串插入到原字串中指定的位置
範例:
var str = "world"
str.insert(",", at: str.startIndex)
// str == ",hello"
str.insert(contentsOf: "hello", at: str.startIndex)
// str == "hello,worlds"
取代指定範圍內字串
名稱: replaceSubrange(_:with:)
說明: 藉由範圍運算子「…」或「..<」,將指定範圍內的字串用另外一個字串取代。
範例:
var str = "today"
let begin = str.index(str.startIndex, offsetBy: 1)
let end = str.index(str.endIndex, offsetBy: -2)
str.replaceSubrange(begin...end, with: "zzz")
// str == "tzzzy"
刪除特定位置字元
名稱: remove(at:)
說明: 根據索引值刪除特定位置字元
範例: 將字串中的第二個字元刪除
var str = "today"
let index = str.index(str.startIndex, offsetBy: 1)
str.remove(at: index)
// str == "tday"
刪除固定位置字元
名稱: removeFirst()、removeFirst(_:)、removeLast()、removeLast(_:)
說明: 這四個函數的功能分別為:刪除第一個字、刪除開頭n個字、刪除最後一個字、刪除最後n個字。
範例:
var str = "today"
str.removeFirst(2)
// str == "day"
刪除指定範圍內字串
名稱: removeSubrange(_:)
說明: 藉由範圍運算子「…」或「..<」刪除範圍內的字串。
範例: 下面範例只留下頭尾兩字元,中間全部刪除。
var str = "today"
let begin = str.index(str.startIndex, offsetBy: 1)
let end = str.index(str.endIndex, offsetBy: -2)
str.removeSubrange(begin...end)
// str == "ty"
刪除特定字元
名稱: filter(_:)
說明: 刪除字串中的特定字元,刪除後產生新字串(String型態)傳回。
範例: 以下範例只留下字元C與D,其他刪除。
let str = "ABCDECHI"
let newstr = str.filter {
if $0 == "C" || $0 == "D" {
return true
}
return false
}
print(newstr)
// Prints "CDC"
刪除開頭特定字元
名稱: drop(while:)
說明: 在closure中刪除第一個false以前的所有字元,結果以Substring型態傳回。
範例: 以下程式會刪除字串開頭的空格。
let str = " tom@mail.com"
let substr = str.drop(while: {
$0 == " "
})
print(substr)
// Prints "tom@mail.com"
刪除固定位置字元
名稱: dropFirst()、dropFirst(_:)、dropLast()、dropLast(_:)
說明: 這四個函數的功能分別為:刪除第一個字、刪除開頭n個字、刪除最後一個字、刪除最後n個字。結果以Substring型態傳回。
範例:
let str = "today"
let newstr = str.dropFirst(2)
// newstr == "day"
大小寫
名稱: uppercased()、lowercased()
說明: 根據原字串,建立新的全大寫或全小寫字串,產生的字串型態為String。
範例:
let str = "toDAY"
let upperCase = str.uppercased()
let lowerCase = str.lowercased()
// upperCase == "TODAY"
// lowerCase == "today"
判斷是否特定字串開頭或特定字串結尾
名稱: hasPrefix(_:)、hasSuffix(_:)
說明: hasPrefix(_:)用來判斷字串是否為某個字串開頭;hasSuffix(_:)用來判斷字串是否為某個字串結尾。
範例:
let str = "today is a good day"
print(str.hasPrefix("today"))
// Prints "true"
print(str.hasSuffix("day"))
// Prints "true"
分割
名稱: split(separator:)、split(separator: maxSplits:)
說明: 將字串根據某個字元分割,分割結果以陣列型態傳回。參數maxSplits表示分割幾次。
範例:
let str = "today is a good day"
let array1 = str.split(separator: " ")
print(array1)
// Prints ["today", "is", "a", "good", "day"]
let array2 = str.split(separator: " ", maxSplits: 1)
print(array2)
// Prints ["today", "is a good day"]
字串取代
名稱: replacingOccurrences(of: with:)
說明: 將字串中指定字串全部換成另外一個字串。
範例:
let str = "today is a good good day"
let newstr = str.replacingOccurrences(of: "good", with: "bad")
// newstr == "today is a bad bad day"
頭尾去空白
名稱: trimmingCharacters(in:)
說明: 移除字串中頭尾特定字元,例如SPACE、TAB與換行,結果以新字串(型態為Sring)傳回。參數值whitespacesAndNewlines表示要移除空白與換行,whitespaces表示僅移除空白,newlines表示僅移除換行。還有一些其他的參數值,例如lowercaseLetters表示移除頭尾小寫字元…等。
範例:
let str = " \ttom@mail.com \n\n"
let newstr = str.trimmingCharacters(in: .whitespacesAndNewlines)
// newstr == "tom@mail.com"